大模型的定义
大模型是指具有数千万甚至数亿参数的深度学习模型。近年来,随着计算机技术和大数据的快速发展,深度学习在各个领域取得了显著的成果,如自然语言处理,图片生成,工业数字化等。为了提高模型的性能,研究者们不断尝试增加模型的参数数量,从而诞生了大模型这一概念。
大模型通常由深度神经网络构建而成,拥有数十亿甚至数千亿个参数。大模型的设计目的是为了提高模型的表达能力和预测性能,能够处理更加复杂的任务和数据。
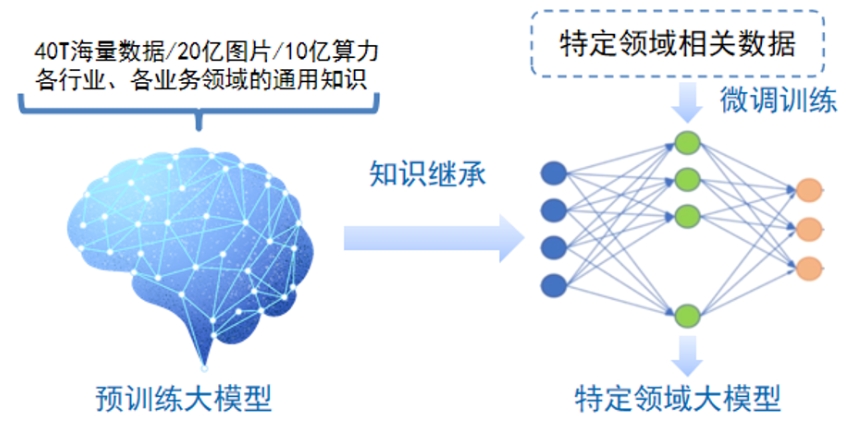
大模型采用预训练+微调的训练模式,在大规模数据上进行训练后,能快速适应一系列下游任务的模型。
大模型和小模型的区别
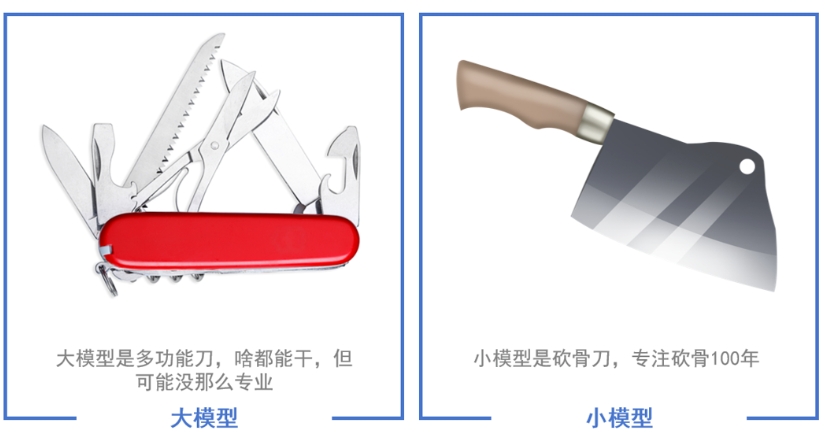
大模型和小模型在应用方面最大的区别是大模型偏向于全能化、通用化,而小模型一般偏向于解决某一垂直领域中的某个具体问题。比如一个图像识别小模型专门训练用来识别车牌号,对车牌号可以有很好的识别精度。但是一个图像识别大模型不仅可以识别车牌号,还可以识别我们生活中碰到的大部分图片,而且站在我们人类的视角来看,他似乎对图片中的内容有自己的理解,看起来拥有更高的智能化水平。
另外相比小模型来说,大模型通常具有更多的参数,能够学习更复杂的特征和模式。同时大模型的训练数据集也会更大,架构更为复杂,训练起来也需要更高的计算资源。
大模型的分类
按照输入数据类型的不同,大模型主要可以分为以下三大类:
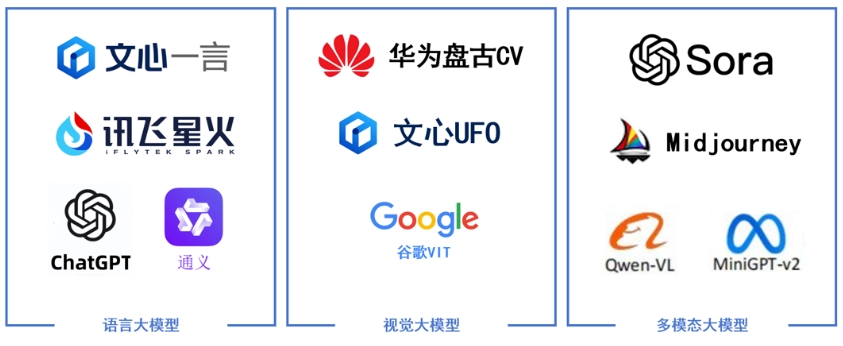
►语言大模型:是指在自然语言处理(NLP)领域中的一类大模型,通常用于处理文本数据和理解自然语言。
►视觉大模型:是指在计算机视觉(CV)领域中使用的大模型,通常用于图像处理和分析。
►多模态大模型:是指能够处理多种不同类型数据的大模型,例如文本、图像、音频等多模态数据。
按照应用领域的不同,大模型主要可以分为 L0、L1、L2 三个层级:
►通用大模型 L0:是指可以在多个领域和任务上通用的大模型。通用大模型就像完成了大学前素质教育阶段的学生,有基础的认知能力,数学、英语、化学、物理等各学科也都懂一点。
►行业大模型 L1:是指那些针对特定行业或领域的大模型。它们通常使用行业相关的数据进行预训练或微调,以提高在该领域的性能和准确度。行业大模型就像选择了某一个专业的大学生,对自己专业下的相关知识有了更深入的了解。
►垂直大模型 L2:是指那些针对特定任务或场景的大模型。它们通常使用任务相关的数据进行预训练或微调,以提高在该任务上的性能和效果。垂直大模型就像研究生,对特定行业下的某个具体领域有比较深入的研究。
大语言模型LLM
大语言模型(Large Language Model,LLM)是大模型的子分类,是专门通过处理大量文本数据来理解和生成人类语言的AI系统,从而执行各种自然语言处理任务,如文本分类、问答、对话、内容总结等。我们最为常见的ChatGPT、百度文心一言、讯飞星火等都属于大语言模型。
大语言模型LLM的基础架构
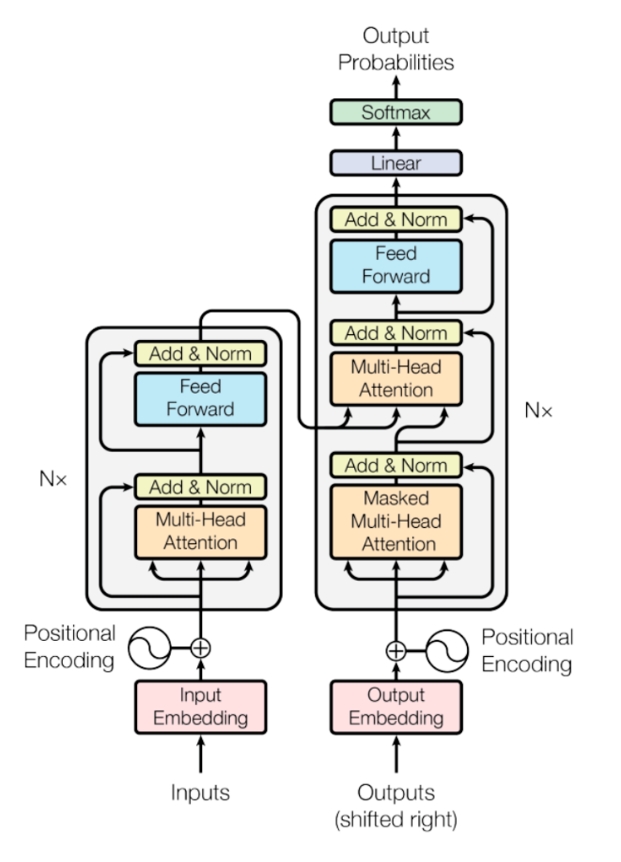
目前流行的大语言模型的架构基本都沿用了当前NLP领域最热门最有效的架构—Transformer架构。Transformer架构来源于谷歌在2017年发表的论文《Attention Is All You Need》,翻译过来就是注意力就是你需要的一切。
注意力机制是大语言模型的核心机制,它让模型在处理文本时,能够同时关注输入中的所有词汇,无论句子长短,都能精准捕捉到远距离的语义关联。例如,在解析“华为公司发布了新款手机”这句话时,模型能够迅速聚焦“华为”与“手机”之间的关系,忽略“公司”或“发布”等词的干扰,这种能力使得大语言模型在处理大段文本、复杂语境时能够真正理解其表达的核心含义。
此外,大语言模型通过位置编码(Positional Encoding)的巧妙设计,模型得以理解文本中的词语位置和顺序,准确把握语言的时序特性,同时保留了高效的并行计算能力。
大语言模型LLM的应用场景
01、知识库问答系统:
通过提问的方式,快速查找企业知识库中的内容,并通过大模型对内容进行总结提炼并给出解决方案;如设备故障查询、设备运检查询、员工智能助手等。
02、问答式BI系统:
通过问答的方式让大模型进行数据库查询,并返回数据结果、可视化图形等内容,供用户进行便捷的数据分析。
03、智能体系统:
将大模型的自然语言能力和小模型的垂直领域能力进行整合,形成企业智能体系统,满足设备故障预测、电力负荷预测、供应商评估分析等智能化应用和预测场景。
大模型的发展是当前人工智能时代科技进步的必然趋势,甚至可以媲美工业革命般的历史意义。大模型这种新技术也帮我们带来了更多生活、工作的有利工具,同时为企业带来了从数字化迈向智能化的可能。因此,在这个数字化发展日新月异的时代,我们只有主动拥抱这种变化,紧跟数字化、智能化潮流,才能确保我们在激烈的竞争中立于不败之地。





























 Tempo商业智能平台
Tempo商业智能平台 Tempo人工智能平台
Tempo人工智能平台 Tempo数据工厂平台
Tempo数据工厂平台 Tempo指标平台
Tempo指标平台 Tempo数据治理平台
Tempo数据治理平台 Tempo主数据管理平台
Tempo主数据管理平台










 陕公网安备 61019002000171号
陕公网安备 61019002000171号



